
Appearance
大家好,我是Ai学习的老章
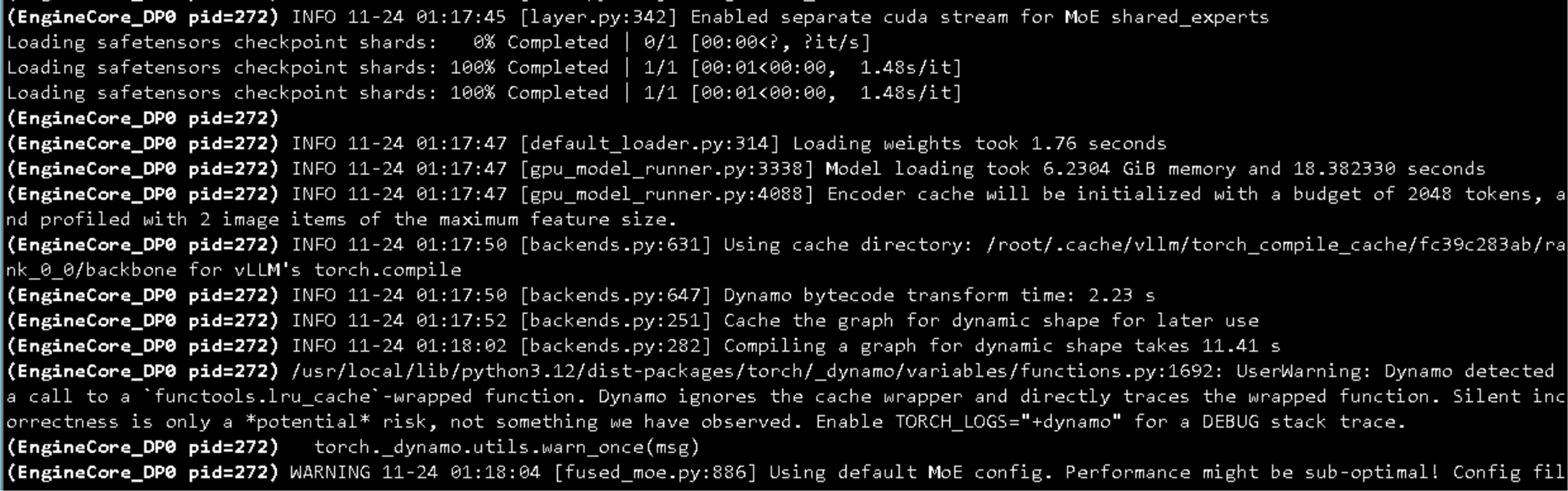
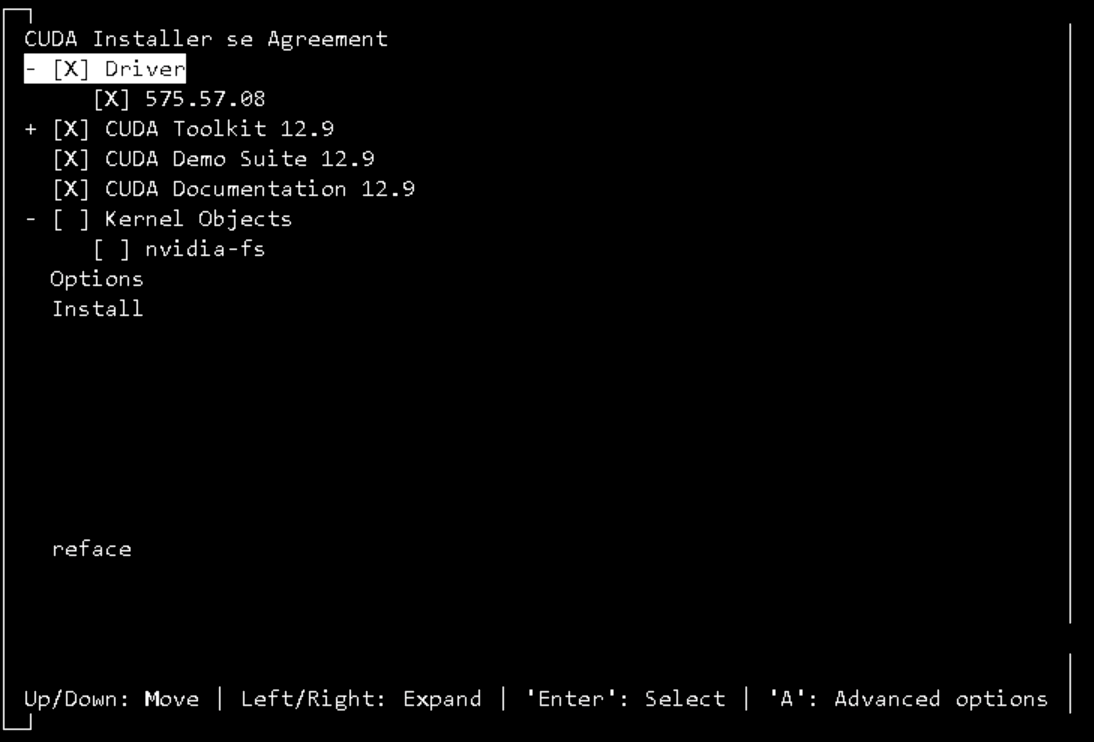
CUDA 升级

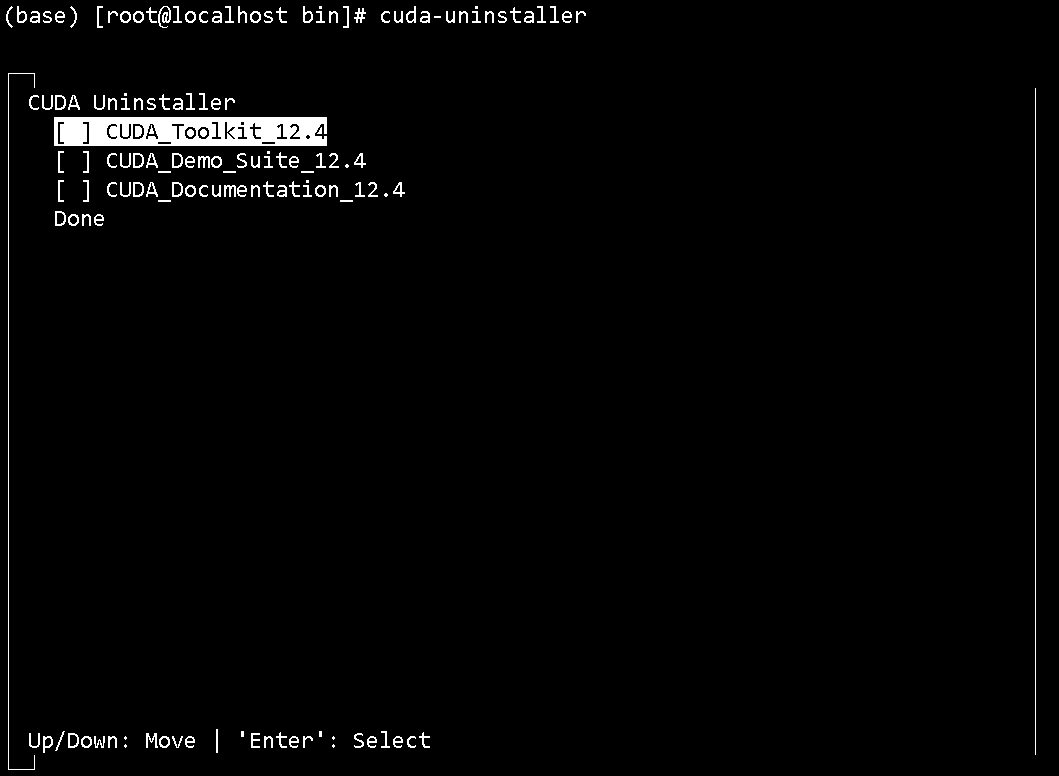
sudo systemctl stop docker
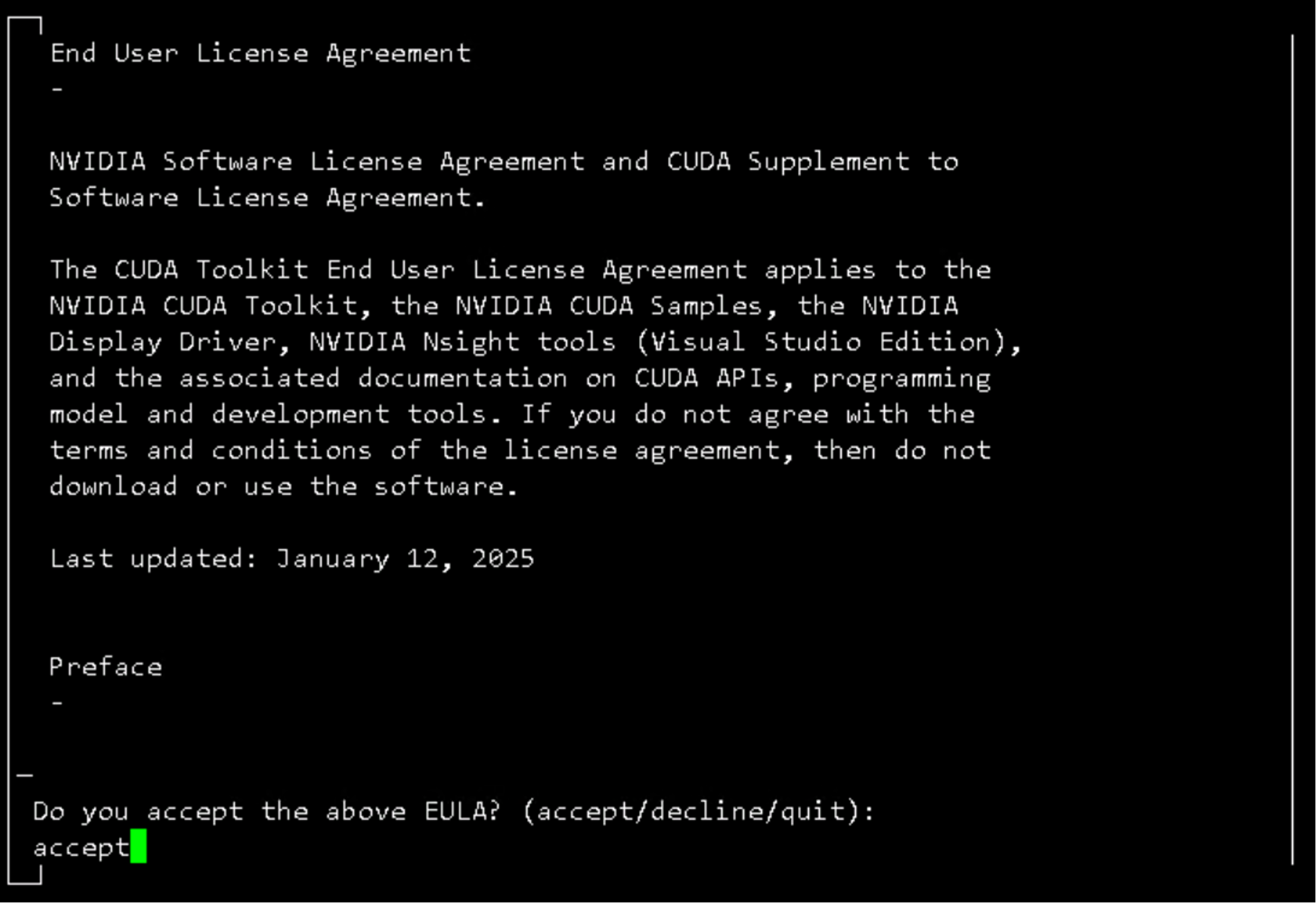
sh cuda_12.9.1_575.57.08_linux.run
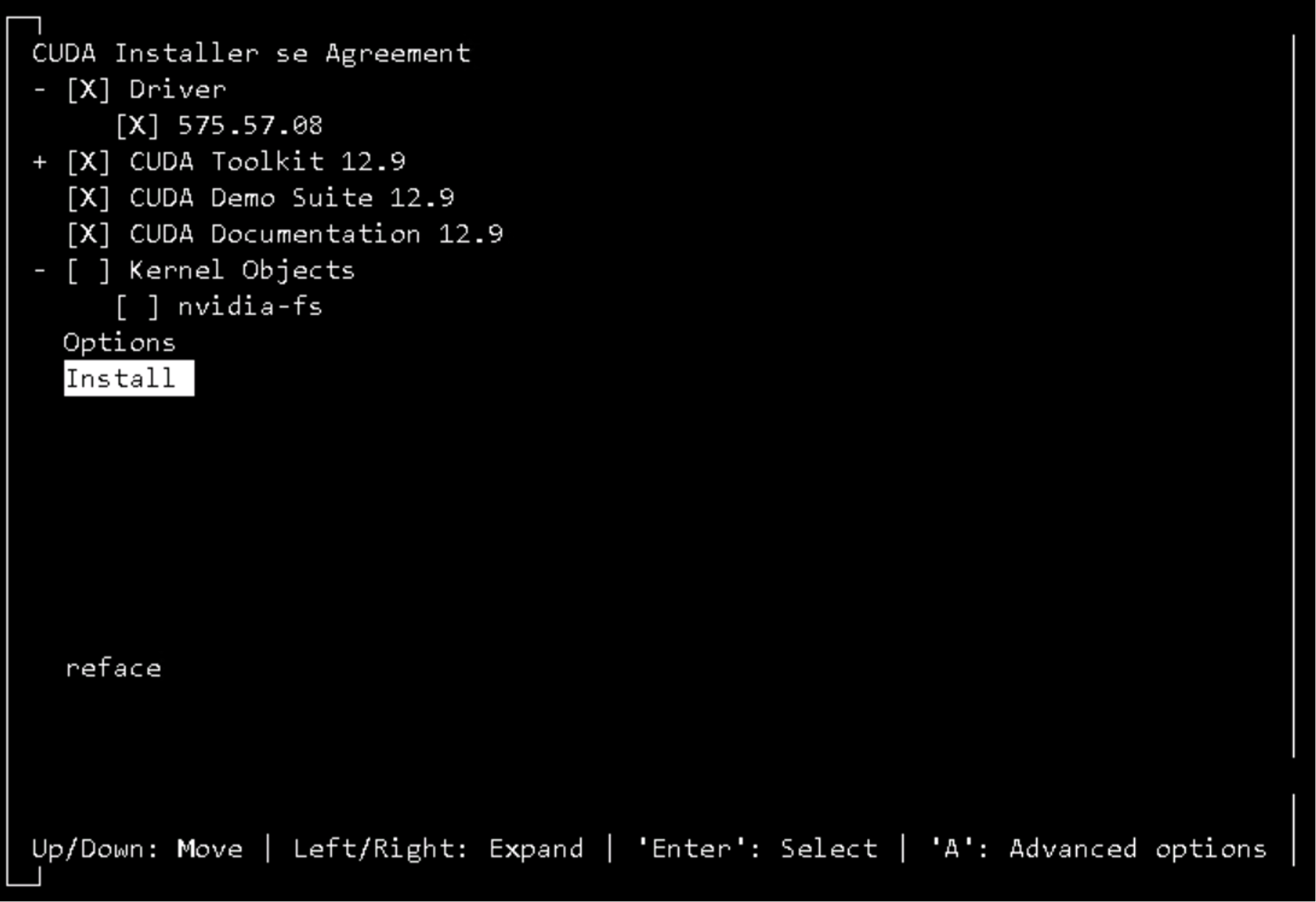
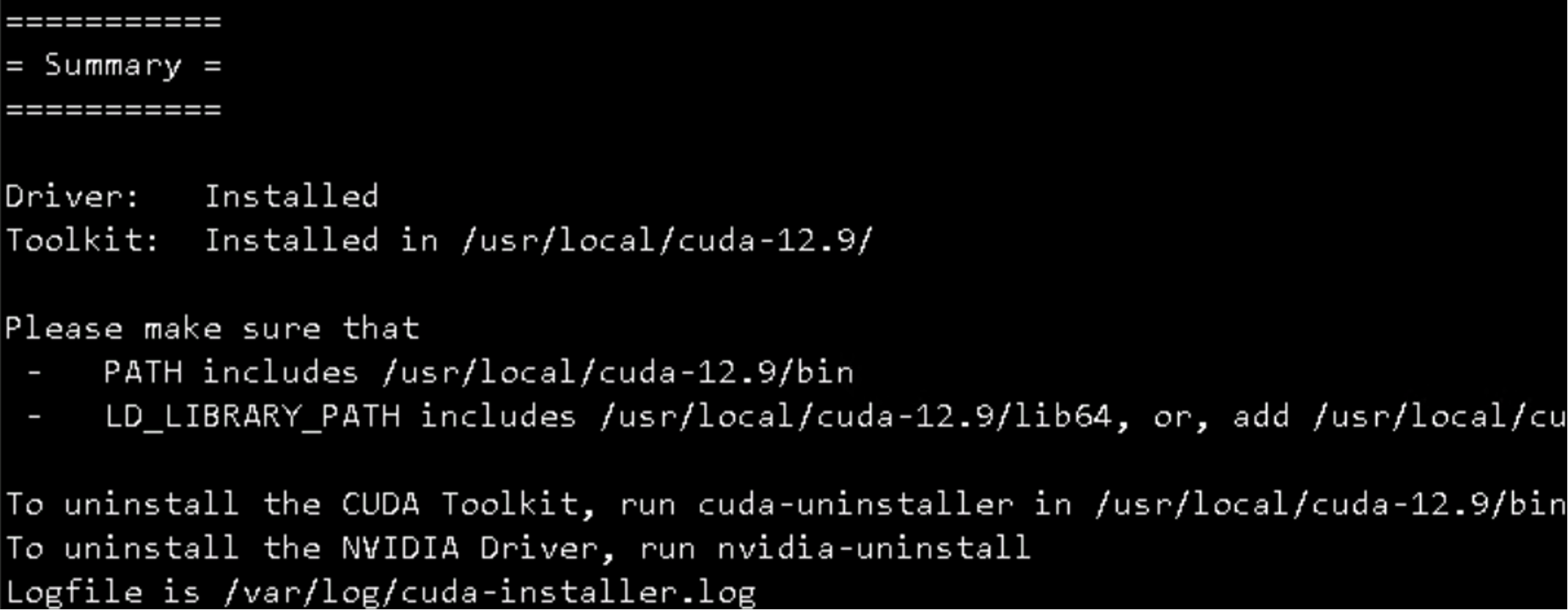
nvcc -V
vi ~/.bashrc
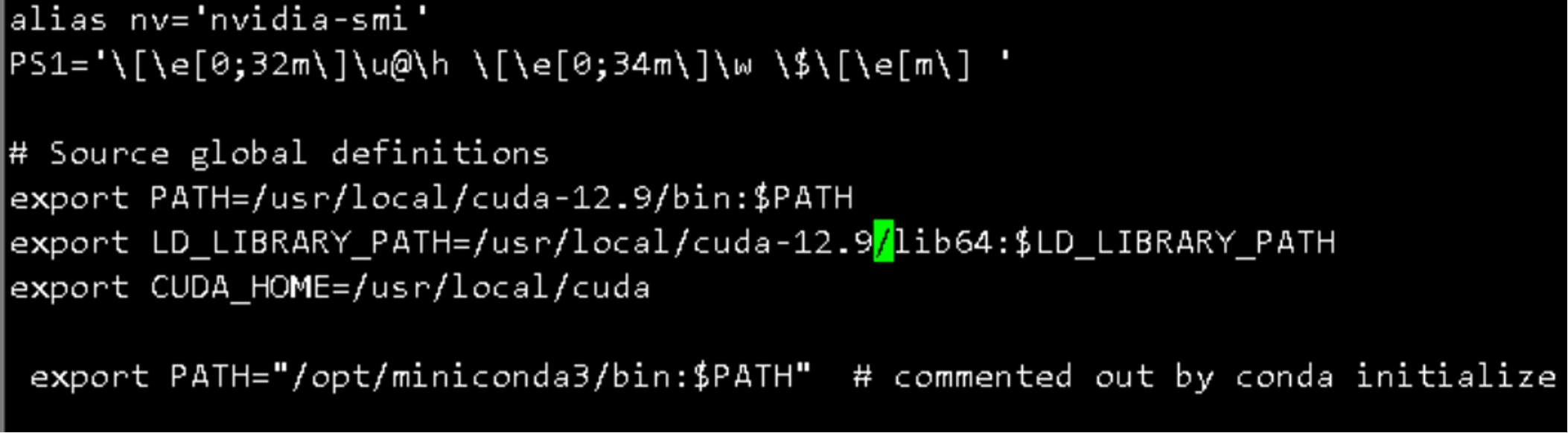
source ~/.bashrc
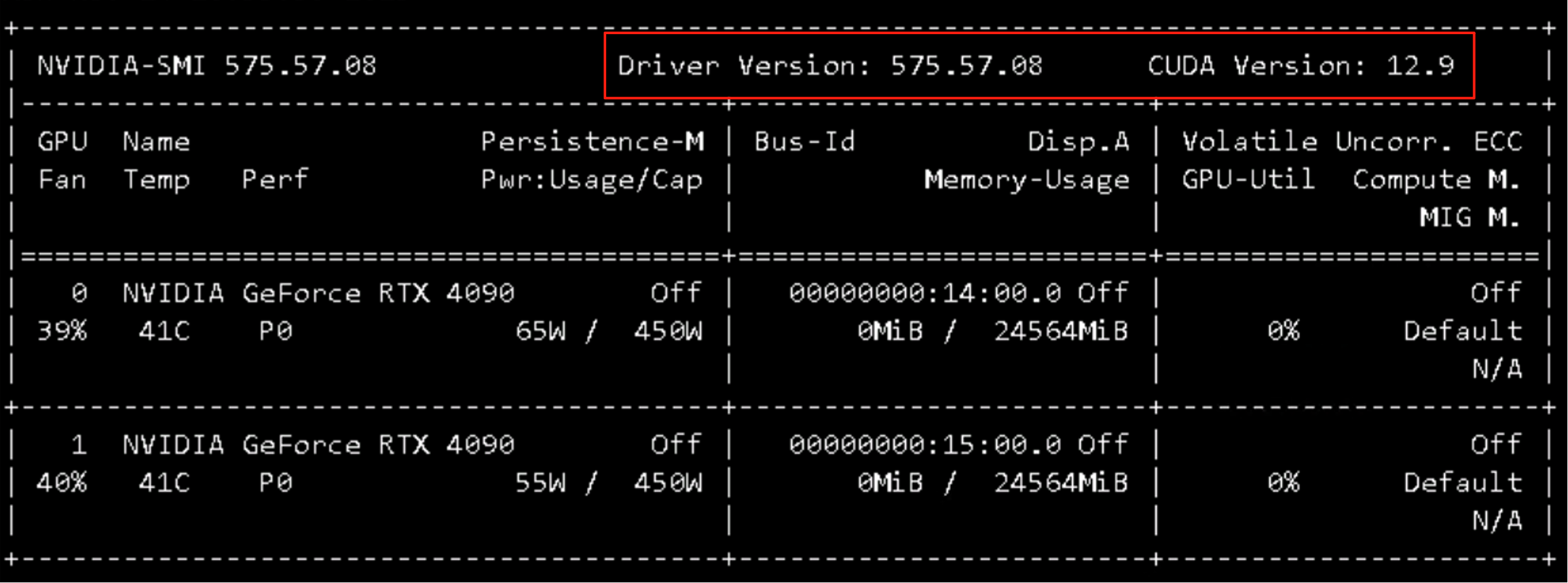
nvcc -V
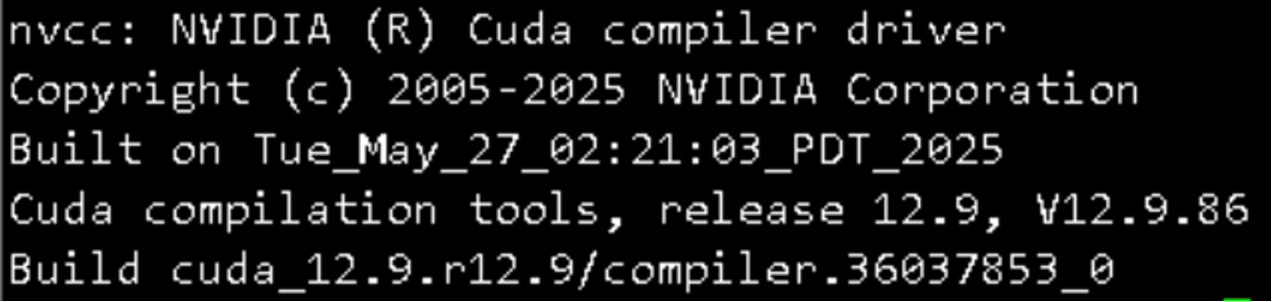
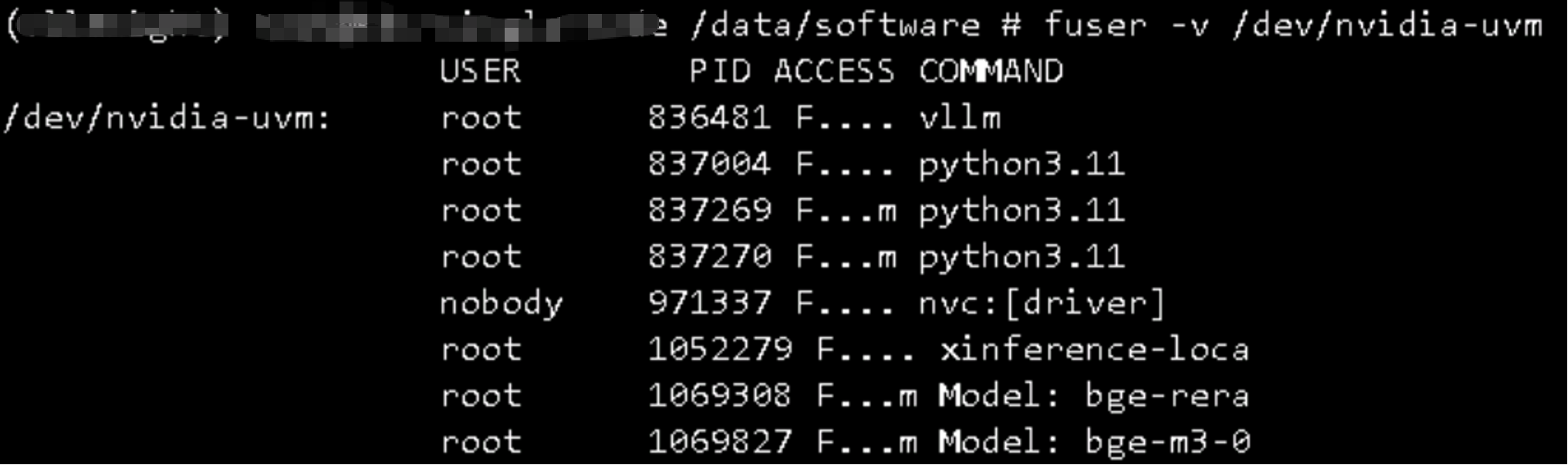
问题1:nvidia-uvm already loaded
要彻底停止 Docker,您需要同时停止服务和套接字。
1 sudo systemctl stop docker.service 2 sudo systemctl stop docker.socket
- 临时停止:sudo systemctl stop docker.service docker.socket
- 永久禁用:sudo systemctl disable docker.service docker.socket
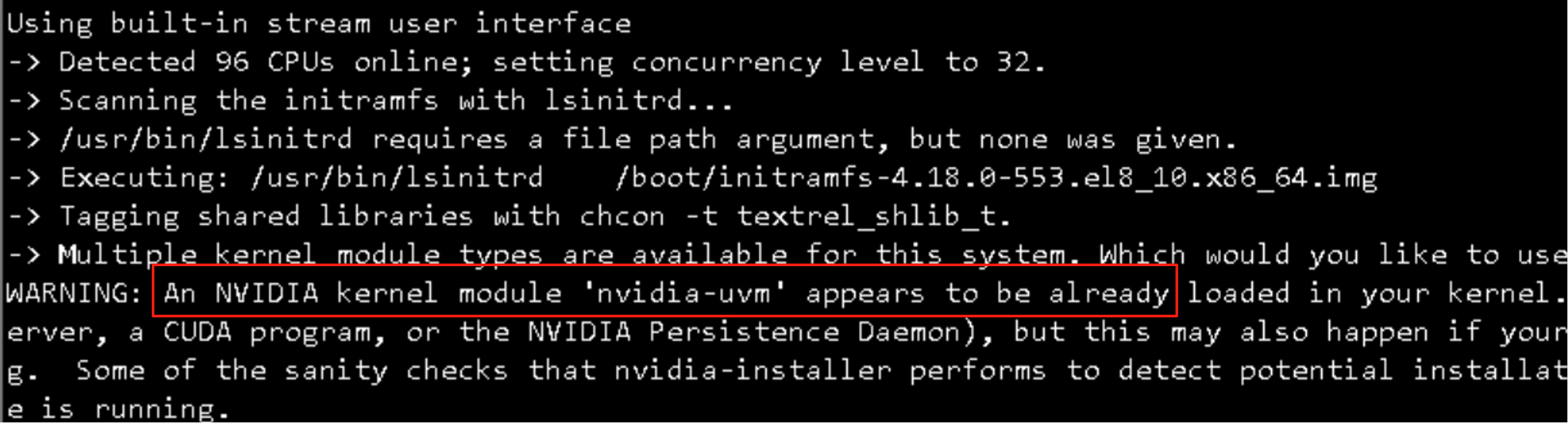
问题2:提示nvidia-drm already loaded
步骤一:切换到纯文本模式(关闭图形界面)
这是最关键的一步。图形界面服务(如 Xorg, GDM, LightDM, SDDM 等)是 nvidia-drm 模块最主要的占用者。我们需要将系统切换到一个不运行图形服务的运行级别。
⚠️ 重要警告:以下命令会关闭服务器的图形用户界面。如果您当前是通过 VNC 或物理桌面连接,您的会话将会中断。通过 SSH 的连接不会中断,这正是我们想要的环境。
在您的 SSH 会话中,执行以下命令:
1 sudo systemctl isolate multi-user.target
- 作用:这个命令会关闭所有图形化服务,将系统带入多用户、纯命令行的状态。
- 备用命令:如果您的系统比较老旧,不使用 systemctl,可以尝试 sudo init 3。
执行后,等待几秒钟,让图形服务完全关闭。
 https://blog.vllm.ai/2025/11/19/docker-model-runner-vllm.html
https://blog.vllm.ai/2025/11/19/docker-model-runner-vllm.html
https://docs.vllm.ai/en/latest/deployment/docker/
![[[email protected]]]
构建 vLLM 的 Docker 镜像(源码)¶
您可以使用提供的 docker/Dockerfile 从源码构建并运行 vLLM。要构建 vLLM,请参阅:
[](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-4-1)# optionally specifies: --build-arg max_jobs=8 --build-arg nvcc_threads=2 [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-4-2)DOCKER_BUILDKIT=1 docker build . \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-4-3) --target vllm-openai \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-4-4) --tag vllm/vllm-openai \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-4-5) --file docker/Dockerfile
注意
默认情况下,vLLM 会为所有 GPU 类型构建以实现最广泛的分发。如果您只是为当前机器上运行的 GPU 类型构建,可以添加参数 --build-arg torch_cuda_arch_list="" 使 vLLM 查找当前 GPU 类型并仅为此类型构建。
如果使用的是 Podman 而不是 Docker,运行 podman build 命令时可能需要通过添加 --security-opt label=disable 来禁用 SELinux 标签,以避免某些 现有问题 。
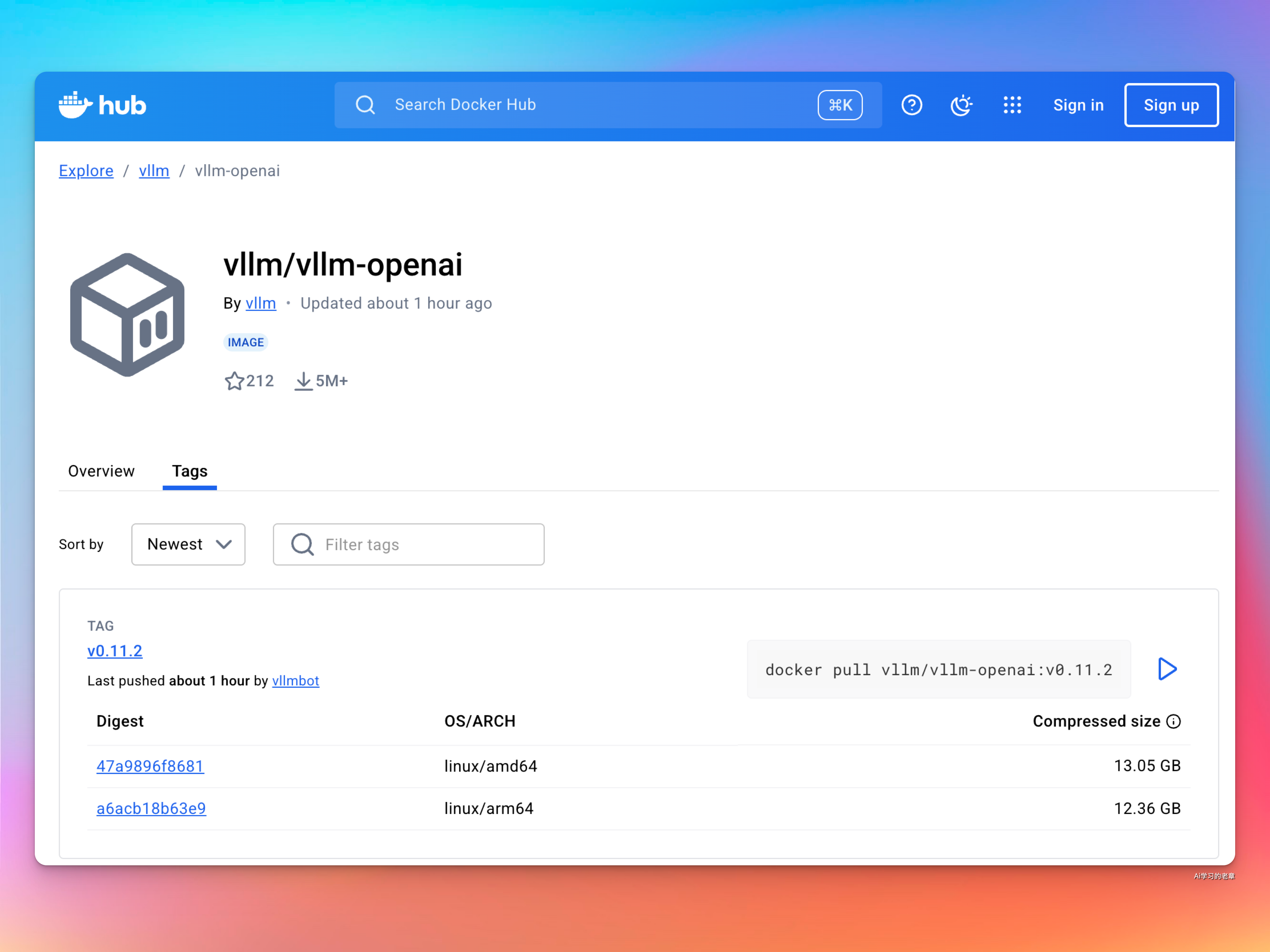
使用 vLLM 的官方 Docker 镜像 ¶
vLLM 提供了一个官方的 Docker 镜像用于部署。该镜像可以用于运行 OpenAI 兼容服务器,并可在 Docker Hub 上找到,地址为 vllm/vllm-openai。
[](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-1)docker run --runtime nvidia --gpus all \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-2) -v ~/.cache/huggingface:/root/.cache/huggingface \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-3) --env "HF_TOKEN=$HF_TOKEN" \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-4) -p 8000:8000 \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-5) --ipc=host \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-6) vllm/vllm-openai:latest \ [](https://docs.vllm.ai/en/latest/deployment/docker/#__codelineno-0-7) --model Qwen/Qwen3-0.6B
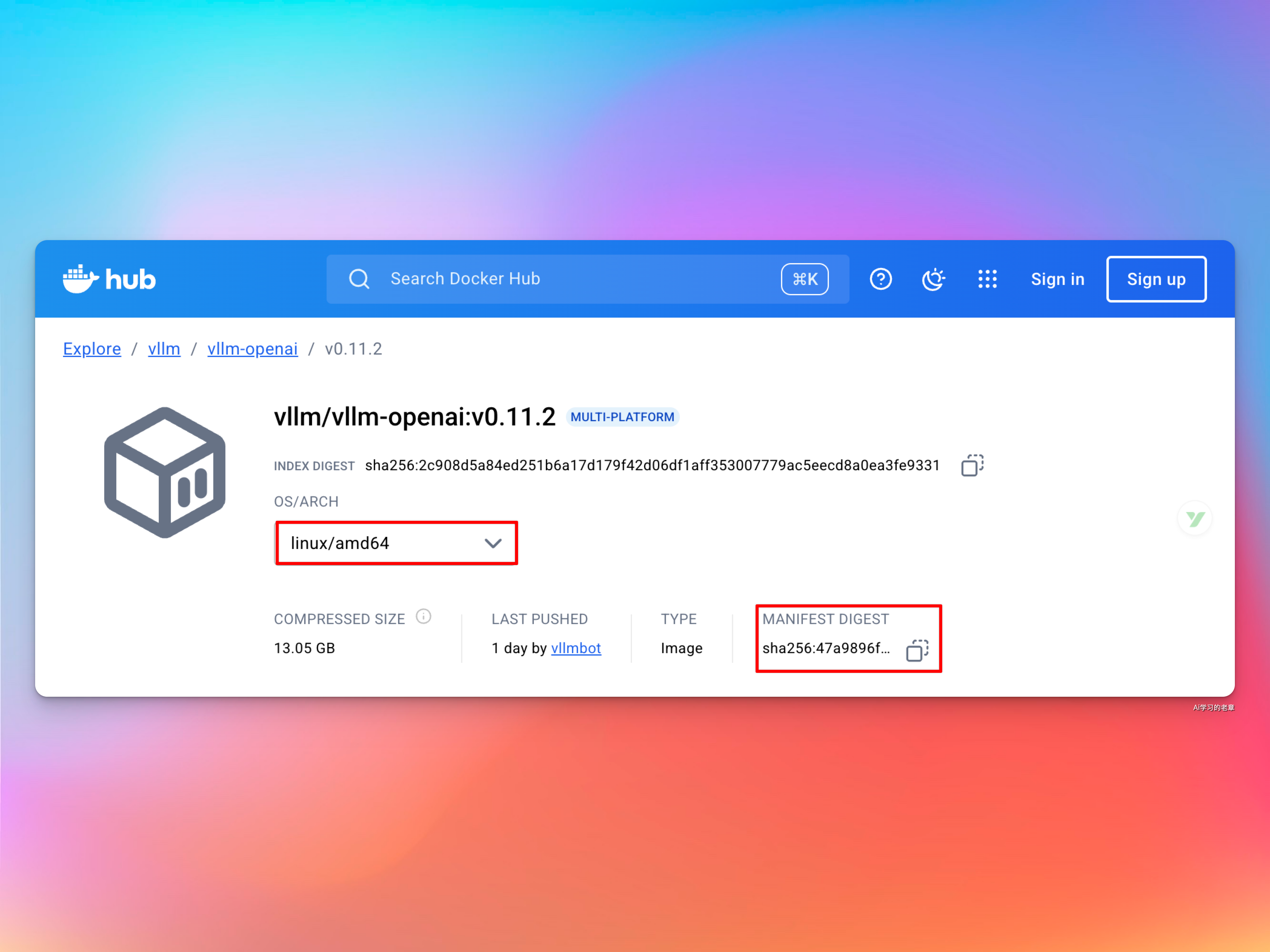
docker save -o vllm-openai-0112.tar vllm/vllm-openai@sha256:47a9896f86818fea323b2d38082758c62d9a0155d6fe6c4dbd7d735c556f680a
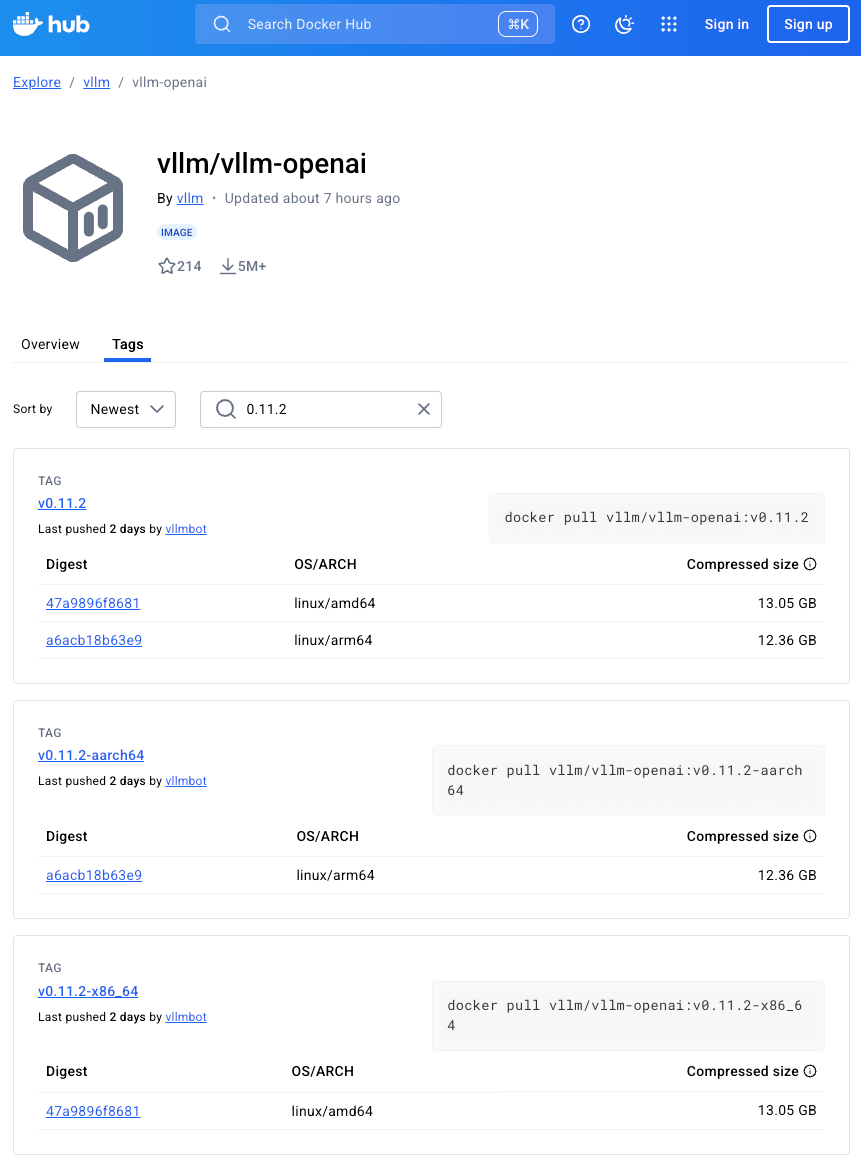
docker pull vllm/vllm-openai:v0.11.2-x86_64
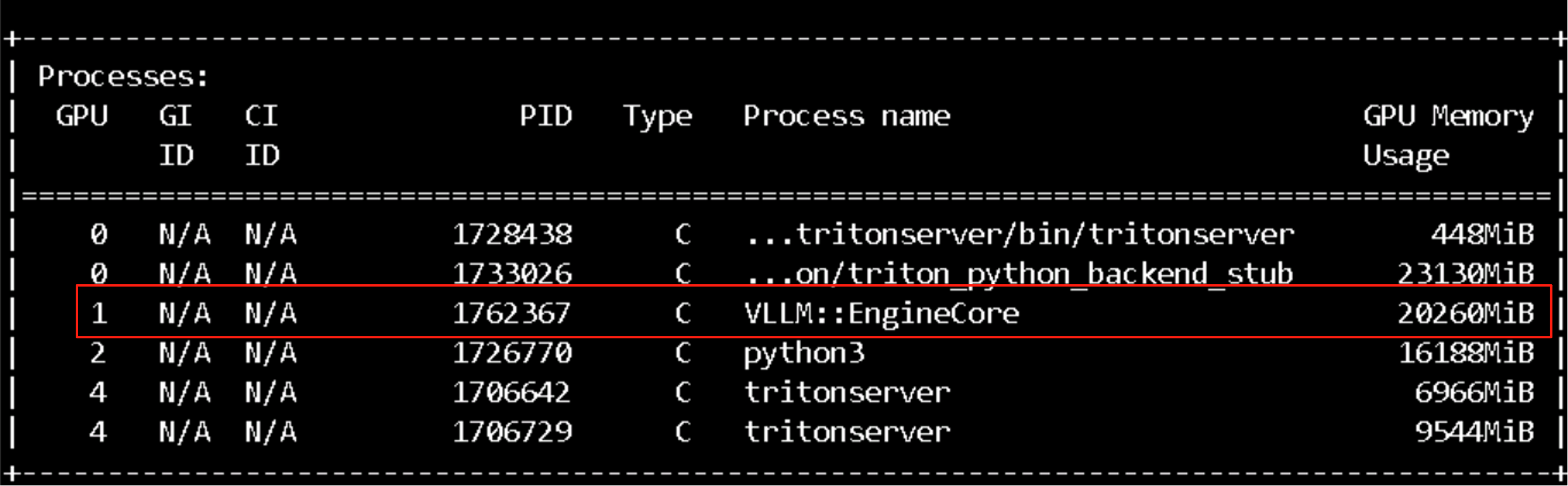
https://github.com/vllm-project/vllm/issues/28016
https://skywork.ai/blog/integrate-deepseek-ocr-python-step-by-step-tutorial/
https://docs.vllm.ai/projects/recipes/en/latest/DeepSeek/DeepSeek-OCR.html#offline-ocr-tasks
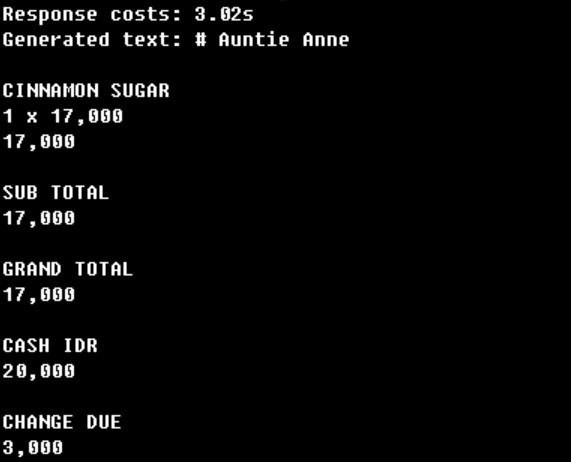
- 使用自定义 logits 处理器以及模型,可获得最佳的 OCR 与 Markdown 生成性能。
- 与多轮聊天场景不同,OCR 任务通常不会从前缀缓存或图像复用中获得显著收益,因此建议关闭这些功能,以避免不必要的哈希和缓存。
- DeepSeek-OCR 在纯文本提示下表现优于指令格式。在官方 DeepSeek-OCR 仓库中可找到适用于各类 OCR 任务的更多示例提示 。
- 根据硬件能力,调整
max_num_batched_tokens以获得更佳的吞吐性能。
