
Appearance
大家好,我是 Ai 学习的老章
前文:# Qwen3-Next,性价比最高的非思考大模型 get,Qwen3-Next 的思考和指令两个模型官方性能测试结果十分诱人。
阿里巴巴 Qwen3 Next 80B:一款开源权重混合推理模型,仅用 3B 活跃参数即可达到 DeepSeek V3.1 级别的智能水平
artificialanalysis.ai 上,它的智能指数都超 DeepSeek-V3.1 了 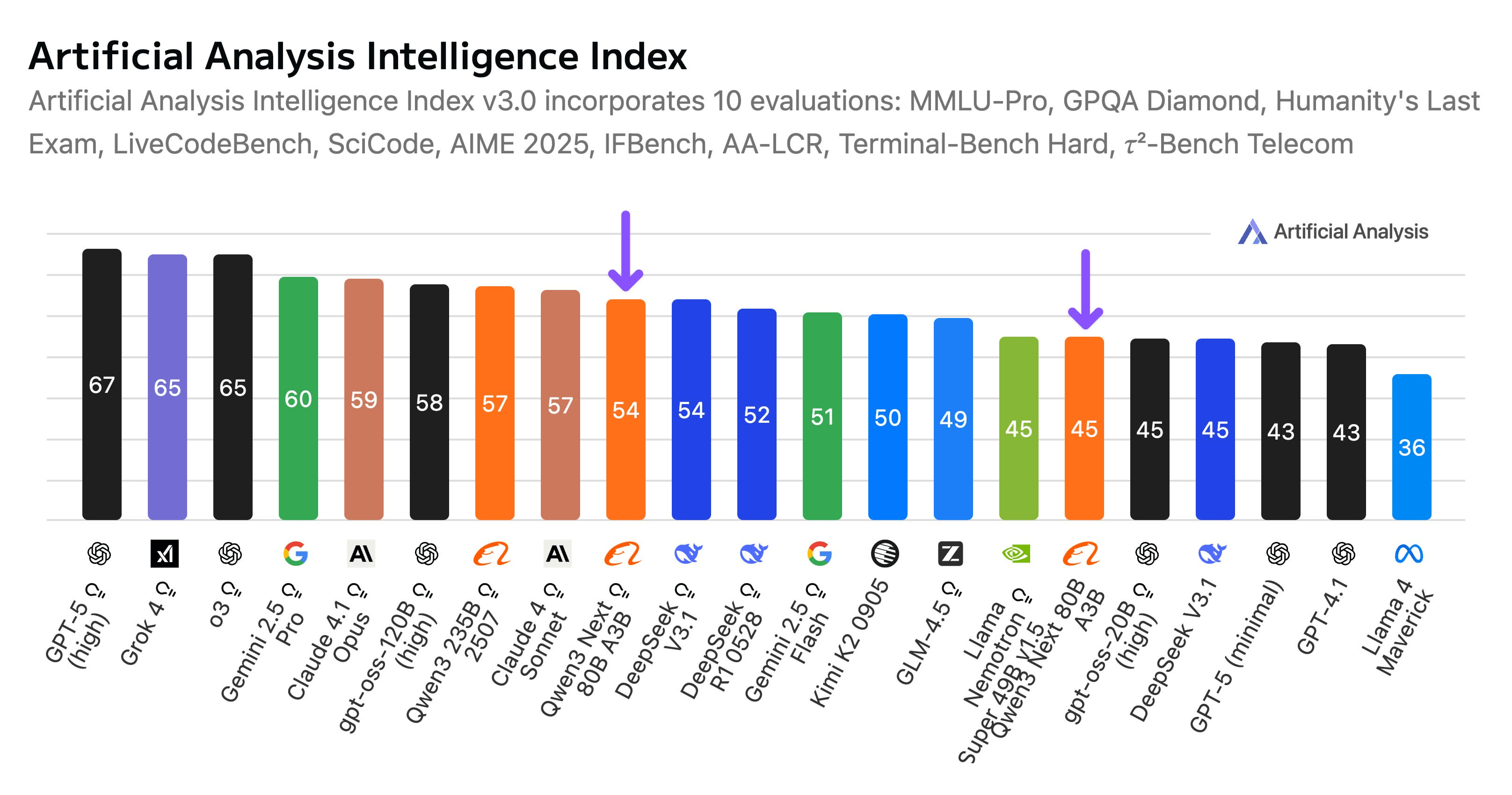
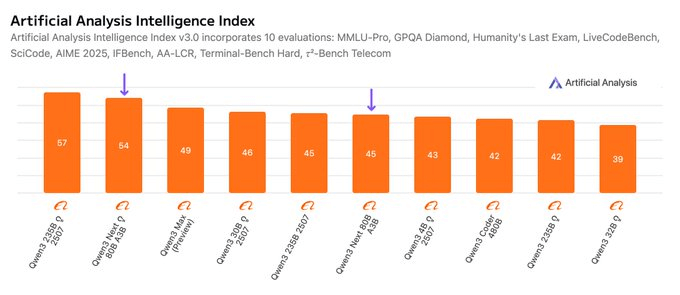
Qwen3 Next 80B(推理版)在 Qwen3 模型家族中智能程度排名第二,介于 Qwen3 235B 2507(推理版)与刚发布的 Qwen3-Max(预览版)之间,后者不使用推理
我早就下好了完整模型文件 -160GB+
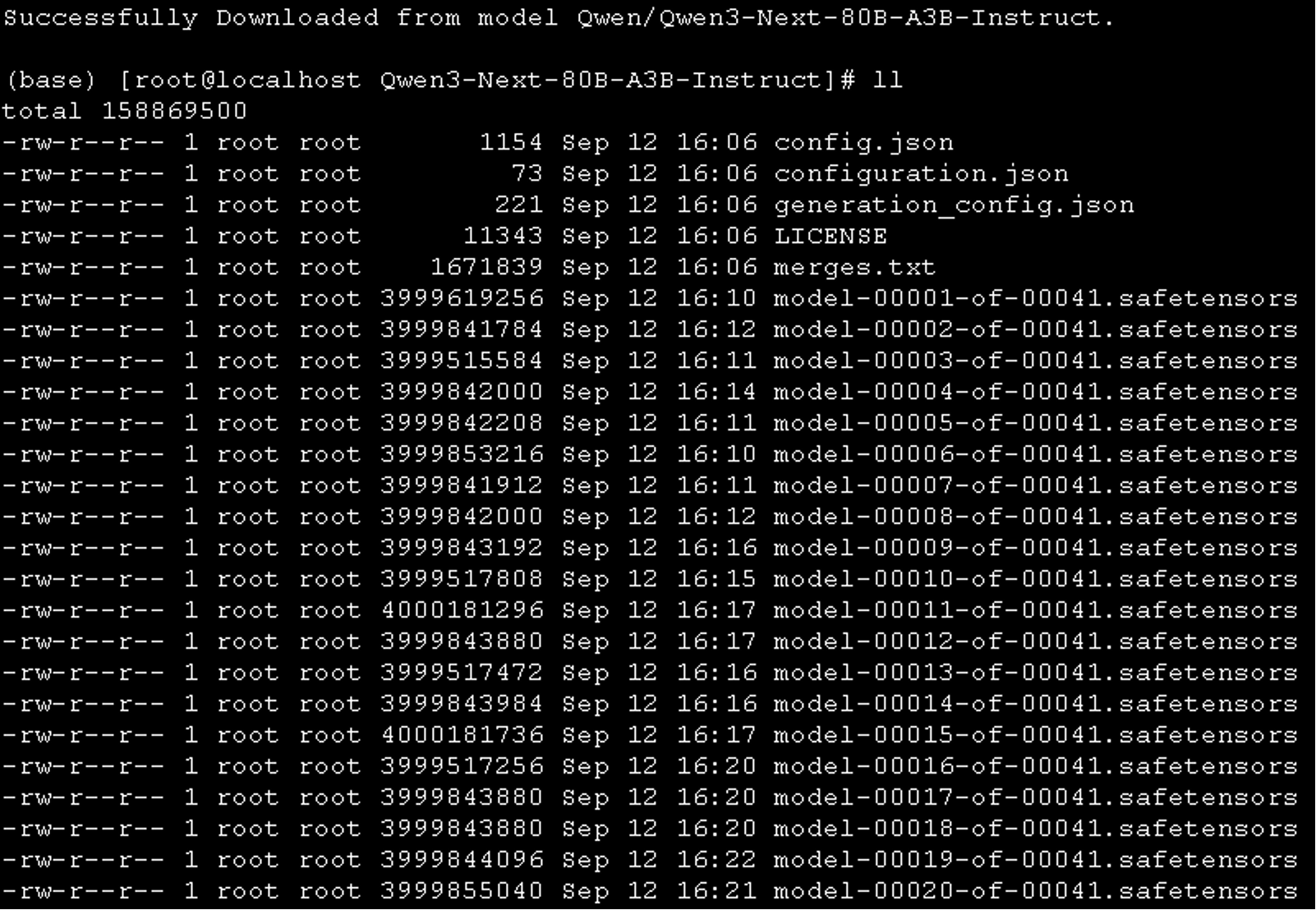
但是后来出了 FP8 量化版,模型文件大小减半,可装入单张 H200 GPU
但是我用 0.10.2 版本的 vLLM 无论怎么改参数都部署失败
无奈就还跑原版,2xH200 开跑
脚本如下:
bash
docker run --rm -d --runtime nvidia --name qwen3-next-tk-server
--ipc=host --gpus '"device=4,5"' -p 8001:8000
-v /data/ai:/models vllm/vllm-openai:v0.10.2
--model /models/Qwen3-Next-80B-A3B-Thinking
--served-model-name qwen3-next-tk-fp8 --port 8000
--max-num-seqs 50 --max-model-len 131072
--tensor-parallel-size 2[! 注意] 默认上下文长度为 256K。如果遇到内存不足(OOM)问题,可以考虑将上下文长度减少到更小的值。但是,由于模型可能需要更长的 token 序列进行推理,我们强烈建议尽可能使用大于 131,072 的上下文长度。
ps:上下文上限跑起需要使用 4 张 H200/H20 或 4 张 A100/A800 GPU 来启动,这里我减半到官方建议的 131072
每卡上模型加载 75GB,耗时 44 秒,KV Cache 49.5GB,峰值激活内存 0.62GB,非 Torch 显存占用 1.38GB,合计 126GB 的样子
运行成功后接入 OpenWebUI,简单测试了一下,略失望,原因有几:
1 是首 token 响应延迟,大几秒的样子才开始回复
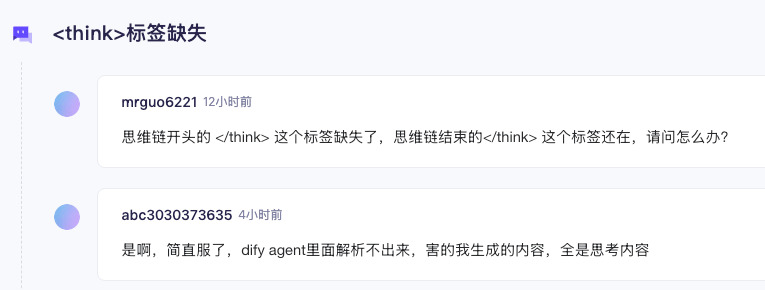
2 是 think 标签缺失,导致整个思考过程无法被识别,直接被打印,而非可隐藏
原因阿里也有解释:
[! 注意] Qwen3-Next-80B-A3B-Thinking 仅支持思考模式。为了强制模型进行思考,默认聊天模板自动包含
\<think\>。因此,模型的输出只包含\<\/think\>而没有显式的\<think\>标签是正常的。
我看魔塔社区也有网友在抱怨,不知道为啥 Qwen 要这么搞,与之前模型保持一致不好吗?无故增加下游应用适配成本
3 是思考过程非常、非常、非常长,长到时常会无限思考
原因阿里还是有解释:
[! 注意] Qwen3-Next-80B-A3B-Thinking 可能会生成比其前身更长的思考内容。我们强烈建议将其用于高度复杂的推理任务。
4 是并发太低了
启动脚本设置了--max-num-seqs 50,但是我用测试工具跑了一下,由于前面三个问题,并发几乎跑不起来,全是 error

5Qwen3-Next 也支持多词元预测(简称 MTP),它既提升了预训练效率,也加快了推理速度。我试了一下,单请求快了点,但是上面四个问题都存在。
bash
docker run --rm -d --runtime nvidia --name qwen3-next-tk-server
--ipc=host --gpus '"device=4,5"' -p 8001:8000
-v /data/ai:/models vllm/vllm-openai:v0.10.2
--model /models/Qwen3-Next-80B-A3B-Thinking
--served-model-name qwen3-next-tk-fp8 --port 8000
--max-num-seqs 50 --max-model-len 131072
--tensor-parallel-size 2
--speculative-config '{"method": "qwen3_next_mtp", "num_speculative_tokens": 2}'
--no-enable-chunked-prefill哪位兄弟本地部署过Qwen3-Next-80B-A3B-Thinking,感受如何?
如有发现我的脚本有问题,欢迎提出,我还是有点不敢相信它会这么不堪。
