
Appearance

大家好,我是Ai学习的老章
Qwen3-235B-A22B-Instruct-2507-GGUF
前文:Qwen3 发了一个「微不足道」的小更新,碾压Kimi K2、DeepSeek V3
但是模型太太太大了
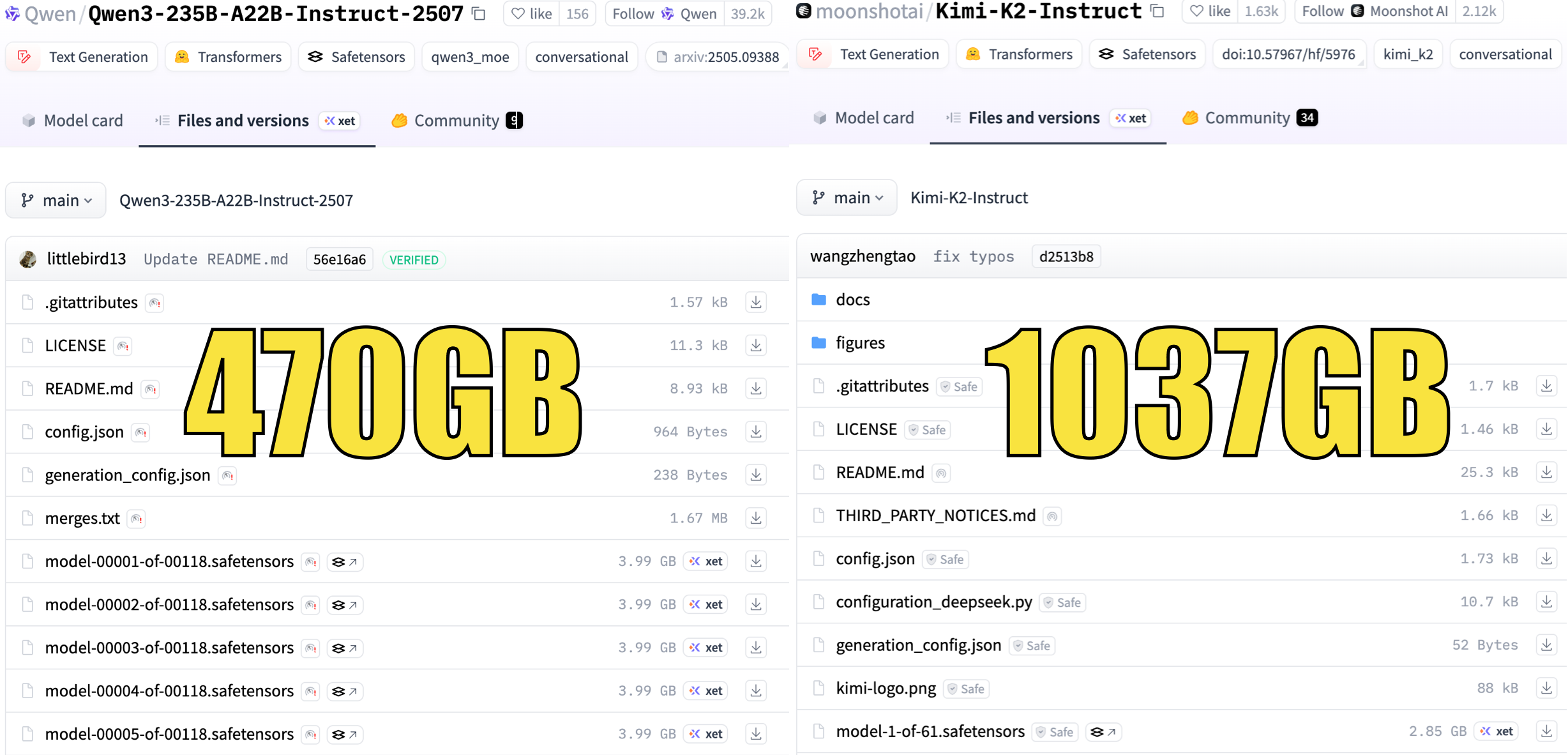
刚说压力给到 【教程】大模型量化界_翘楚_:unsloth
这不,unsloth 各种量化版本全都来了
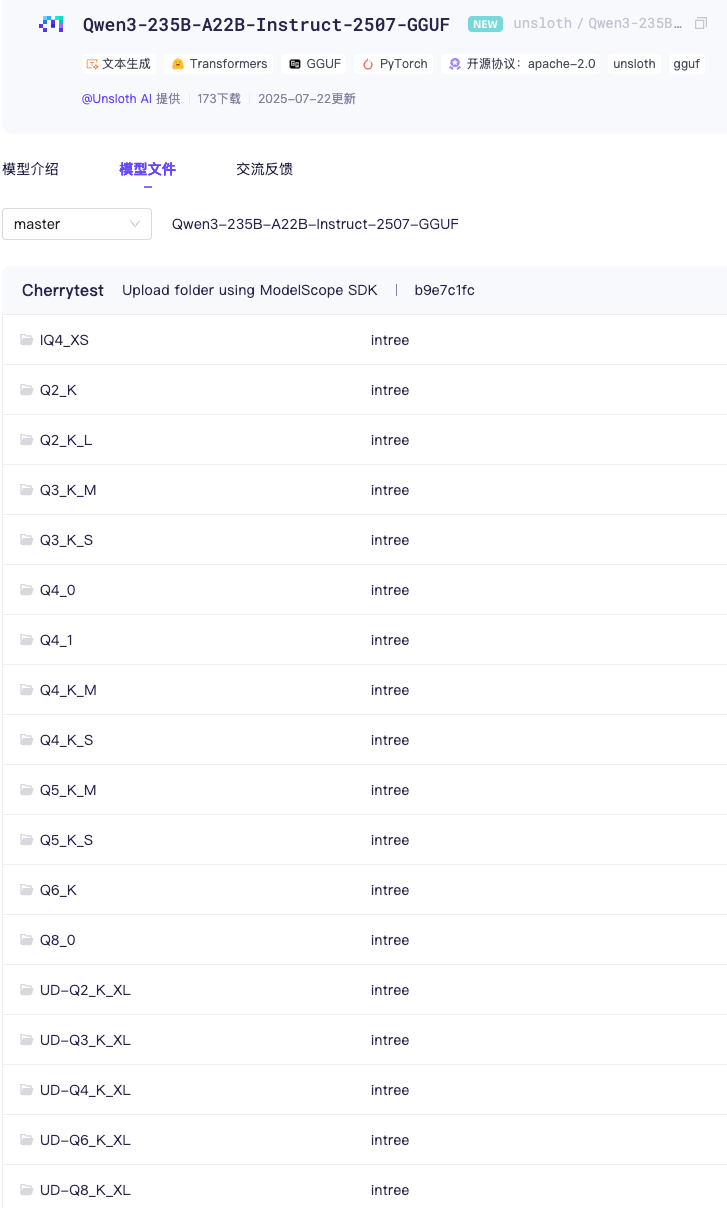
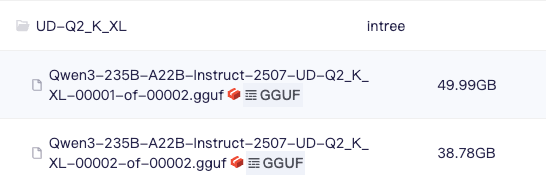
UD-Q2_K_XL 仅需88GB显存
官方FP16的 500GB 显存,官方 FP8 版 240GB
Unsloth Q2 压到了88GB,不愧是大模型量化翘楚
如果稍富一点的哥们可以选大点的,比如经典的Q4_K_M 仅需142 GB
| bit | 模型名 | 大小 |
|---|---|---|
| 2-bit | Q2_K | 85.7 GB |
Q2_K_L | 85.8 GB | |
Q2_K_XL | 88.8 GB | |
| 3-bit | Q3_K_S | 101 GB |
Q3_K_M | 112 GB | |
Q3_K_XL | 104 GB | |
| 4-bit | IQ4_XS | 125 GB |
Q4_K_S | 134 GB | |
Q4_0 | 133 GB | |
Q4_1 | 147 GB | |
Q4_K_M | 142 GB | |
Q4_K_XL | 134 GB | |
| 5-bit | Q5_K_S | 162 GB |
Q5_K_M | 167 GB | |
| 6-bit | Q6_K | 193 GB |
Q6_K_XL | 202 GB | |
| 8-bit | Q8_0 | 250 GB |
Q8_K_XL | 274 GB | |
| 16-bit | BF16 | 470 GB |
⚙️最佳实践
为了达到最佳性能,建议采用以下设置:
- 采样参数:
- 建议使用
Temperature=0.7,TopP=0.8,TopK=20和MinP=0。 - 对于支持的框架,可以在 0 到 2 之间调整
presence_penalty参数以减少无尽重复。然而,使用较高的值可能会偶尔导致语言混合,并略微降低模型性能。
- 建议使用
- 足够的输出长度:建议使用 16,384 个令牌的输出长度,对于指令模型是足够的。
- 标准化输出格式:建议在基准测试时使用提示来标准化模型输出。
- 数学问题:在提示中包含“请逐步推理,并将最终答案放在 \boxed{} 中。”
- 选择题:在提示中添加以下 JSON 结构以标准化响应:“请在
answer字段中仅显示选项字母,例如,"answer": "C"。”
CPU 运行
使用 Llama.cpp 进行优化推理和多种选项。
- 请从 GitHub 这里 获取最新版的
llama.cpp。你也可以参考以下编译说明。如果你没有 GPU 或只想使用 CPU 推理,请将-DGGML_CUDA=ON更改为-DGGML_CUDA=OFF。bashapt-get update apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y git clone https://github.com/ggml-org/llama.cpp cmake llama.cpp -B llama.cpp/build \ -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-gguf-split cp llama.cpp/build/bin/llama-* llama.cpp - 通过 (
pip install huggingface_hub hf_transfer安装后) 下载模型。您可以选择 UD-Q2_K_XL,或其他量化版本。bash# !pip install huggingface_hub hf_transfer import os os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1" from huggingface_hub import snapshot_download snapshot_download( repo_id = "unsloth/Qwen3-235B-A22B-Instruct-2507-GGUF", local_dir = "unsloth/Qwen3-235B-A22B-Instruct-2507-GGUF", allow_patterns = ["*UD-Q2_K_XL*"], ) - 运行模型并尝试
- 编辑
--threads -1以设置 CPU 线程数,--ctx-size262114 以设置上下文长度,--n-gpu-layers 99以在多少层上启用 GPU 卸载。如果您的 GPU 内存不足,请尝试调整这些参数。如果没有 GPU 仅使用 CPU 进行推理,请移除这些参数。
使用
-ot ".ffn_.*_exps.=CPU"将所有 MoE 层卸载到 CPU!这实际上允许您将所有非 MoE 层放在一个 GPU 上,从而提高生成速度。您可以根据 GPU 容量自定义正则表达式以适应更多层。
bash
./llama.cpp/llama-cli \
--model unsloth/Qwen3-235B-A22B-Instruct-2507-GGUF/UD-Q2_K_XL/Qwen3-235B-A22B-Instruct-2507-UD-Q2_K_XL-00001-of-00002.gguf \
--threads 32 \
--ctx-size 16384 \
--n-gpu-layers 99 \
-ot ".ffn_.*_exps.=CPU" \
--seed 3407 \
--prio 3 \
--temp 0.7 \
--min-p 0.0 \
--top-p 0.8 \
--top-k 20看到一个测评: Qwen3 在 SimpleQA 中表现优异,因为它训练得像一辆坦克:庞大、精确且充满事实。它需要大量的内存才能充分发挥性能,但运行起来非常稳定。我认为它确实能减少幻觉并提高回忆能力,尤其是在随机内容方面。如果你追求准确性,这绝对值得期待。
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)图解机器学习 - 中文版(72 张 PNG)ChatGPT 、大模型系列研究报告(50 个 PDF)108页PDF小册子:搭建机器学习开发环境及Python基础 116页PDF小册子:机器学习中的概率论、统计学、线性代数 史上最全!371张速查表,涵盖AI、ChatGPT、Python、R、深度学习、机器学习等
