
Appearance


大家好,我是 Ai 学习的老章
极简结论:Qwen3 是可以本地部署的最强开源写代码大模型
[[2025-04-29-阿里Qwen3 全部情报汇总,本地部署指南,性能全面超越 DeepSeek R1]]
我只有 4 张 4090 显卡,本文尝试本地部署 Qwen3:32B,搭配 OpenwebUI 聊天 Bot,简单看看其推理速度
[TOC]
本地部署
ollama
模型页:https://ollama.com/library/qwen3
运行:ollama run qwen3
其他尺寸,在后面加参数即可,比如:ollama run qwen3:32b
可以在提示词后输入 /no_think 来切换 Ollama 中的无思考模式。
备注⚠️:ollama 运行的是量化版,效果有折扣
vLLM

需要升级到 v0.8.4 以上,最好 v0.8.5
地址:https://github.com/vllm-project/vllm/issues/17327
bash
vllm serve Qwen/Qwen3-235B-A22B-FP8 --enable-reasoning --reasoning-parser deepseek_r1 --tensor-parallel-size 4SGLang
需要升级到SGLang 0.4.6.post1
地址:https://github.com/sgl-project/sglang
bash
pip3 install "sglang[all]>=0.4.6.post1"
python3 -m sglang.launch_server --model Qwen/Qwen3-235B-A22B --tp 8 --reasoning-parser qwen3
python3 -m sglang.launch_server --model Qwen/Qwen3-235B-A22B-FP8 --tp 4 --reasoning-parser qwen3
CPU 部署
llama.cpp
可以用 llama.cpp 运行起 Qwen3 量化版本、动态量化版本!
地址:https://huggingface.co/collections/unsloth/qwen3-680edabfb790c8c34a242f95

KTransformer
Xeon 铂金 4 代 + 4090 运行 Qwen3-235B-A22B 单个请求可以达到 13.8 token/s, 4 个请求并行可以达到总计 24.4 token/s
地址:http://github.com/kvcache-ai/ktransformers/blob/main/doc/en/AMX.md
Mac 部署
Mac 上也可以跑 Qwen3 了
地址:https://github.com/ml-explore/mlx-lm/commit/5c2c18d6a3ea5f62c5b6ae7dda5cd9db9e8dab16
shell
pip install -U mlx-lm
# or
conda install -c conda-forge mlx-lm支持设备
- iPhone: 0.6B, 4B
- Macbook: 8B, 30B, 3B/30B MoE
- M2, M3 Ultra: 22B/235B MoE
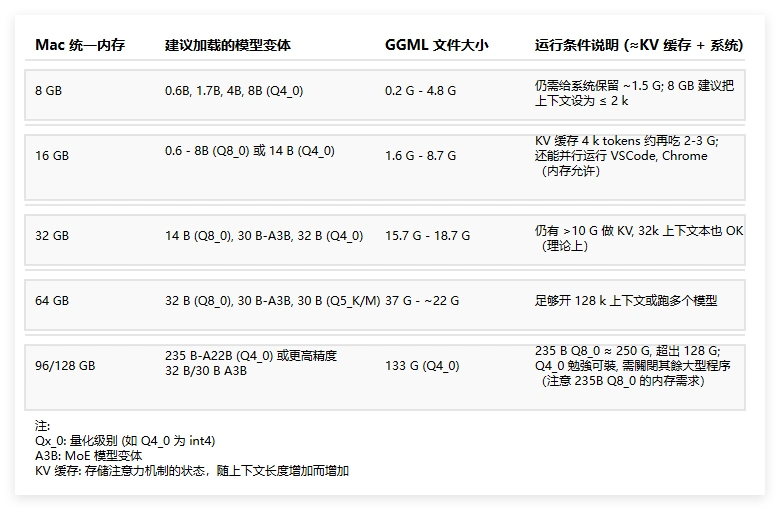 有网友测试
有网友测试 Qwen3-235B-A22B-4bit 量化版本在 Apple Mac Studio M2 Ultra 能跑到 28 toks/sec,大概占用 132GB 内存
下载模型
模型文件:https://modelscope.cn/models/Qwen/Qwen3-32B/files
在下载前,先通过如下命令安装 ModelScope
pip install modelscope
命令行下载完整模型库
modelscope download --model Qwen/Qwen3-32B
下载单个文件到指定本地文件夹(以下载 README.md 到当前路径下“dir”目录为例)
modelscope download --model Qwen/Qwen3-32B README.md --local_dir ./dir
模型大小约 64GB

模型部署
用 vllm 拉起大模型,我有 4 张 4090 显卡,tensor-parallel-size 设置为 4
bash
pip install --upgrade vllm
vllm serve . --served-model-name Qwen3:32B --port 3001 --enble-reasoning --reasoning-parse deepseek_r1 --tensor-parallel-size 4
卡没被占满,还有空余拉起 reranker 模型
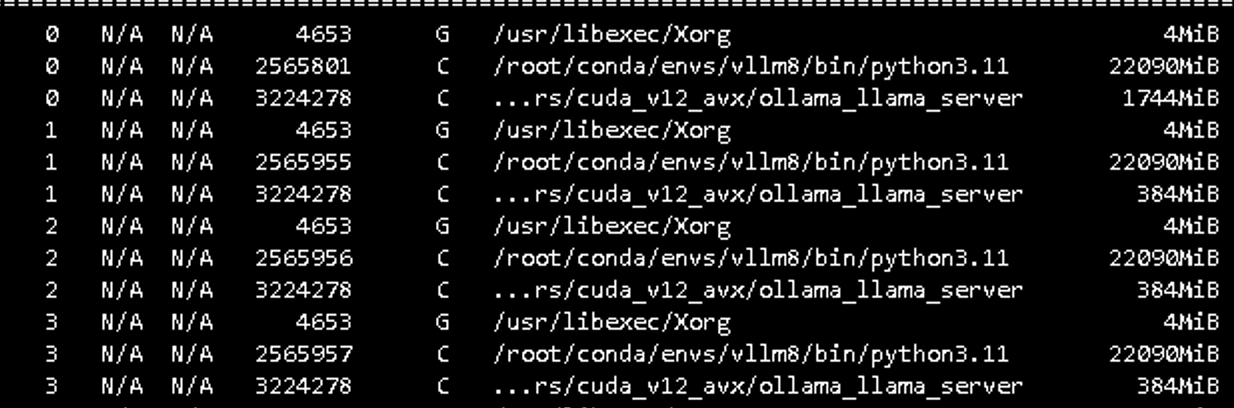
openwebui 聊天助手
OpenWebUI 旨在为 AI 和 LLMs 构建最佳用户界面,为那些互联网访问受限的人提供利用 AI 技术的机会。OpenWebUI 通过 Web 界面本地运行 LLMs,使 AI 和 LLMs 更安全、更私密。
安装 openwebui 是我见过所有 chatbot 中最简单的了
shell
# 安装
pip install open-webui
# 启动
open-webui serve浏览器打开 http://locahost:8080
如果是服务器部署,把 localhost 改为服务器 ip
正常注册登陆
右上角点击头像,点击管理员面板
点击设置 - 外部链接,照着抄一下,api key 随便填写 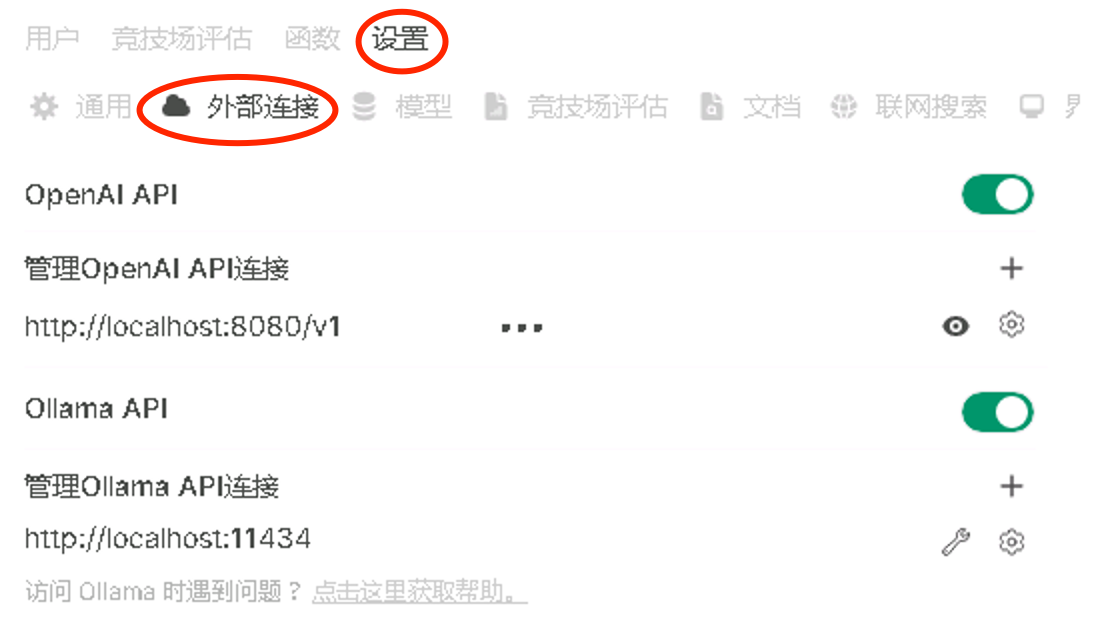
然后回到前端,左上角添加模型那里就可以找到 Qwen3:32B 了
teminal 页面会实时输出模型推理时的性能
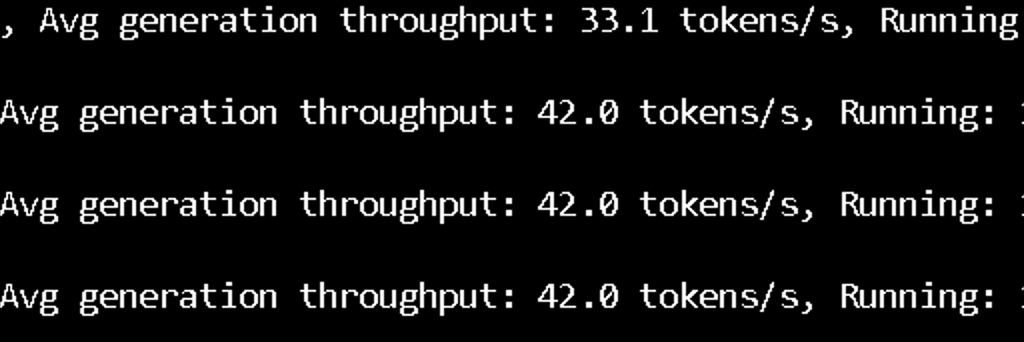
速度还蛮快的,如果开启 reasoning 会慢很多,关闭的话,vllm 那里改成下面即可
vllm serve . --served-model-name Qwen3:32B --port 3001 --tensor-parallel-size 4
测试
我看了一些网友评价,很多说效果远远不如官方公布的结果,还有说幻觉严重
有些是直接用 ollama 运行的量化版,效果不好很正常
有些是在官方网站上测试的,这个就见仁见智了,我还是觉得个例的参考价值不大
用脑经急转弯和弱智吧的问题去测试大模型,属实脑经不转弯。
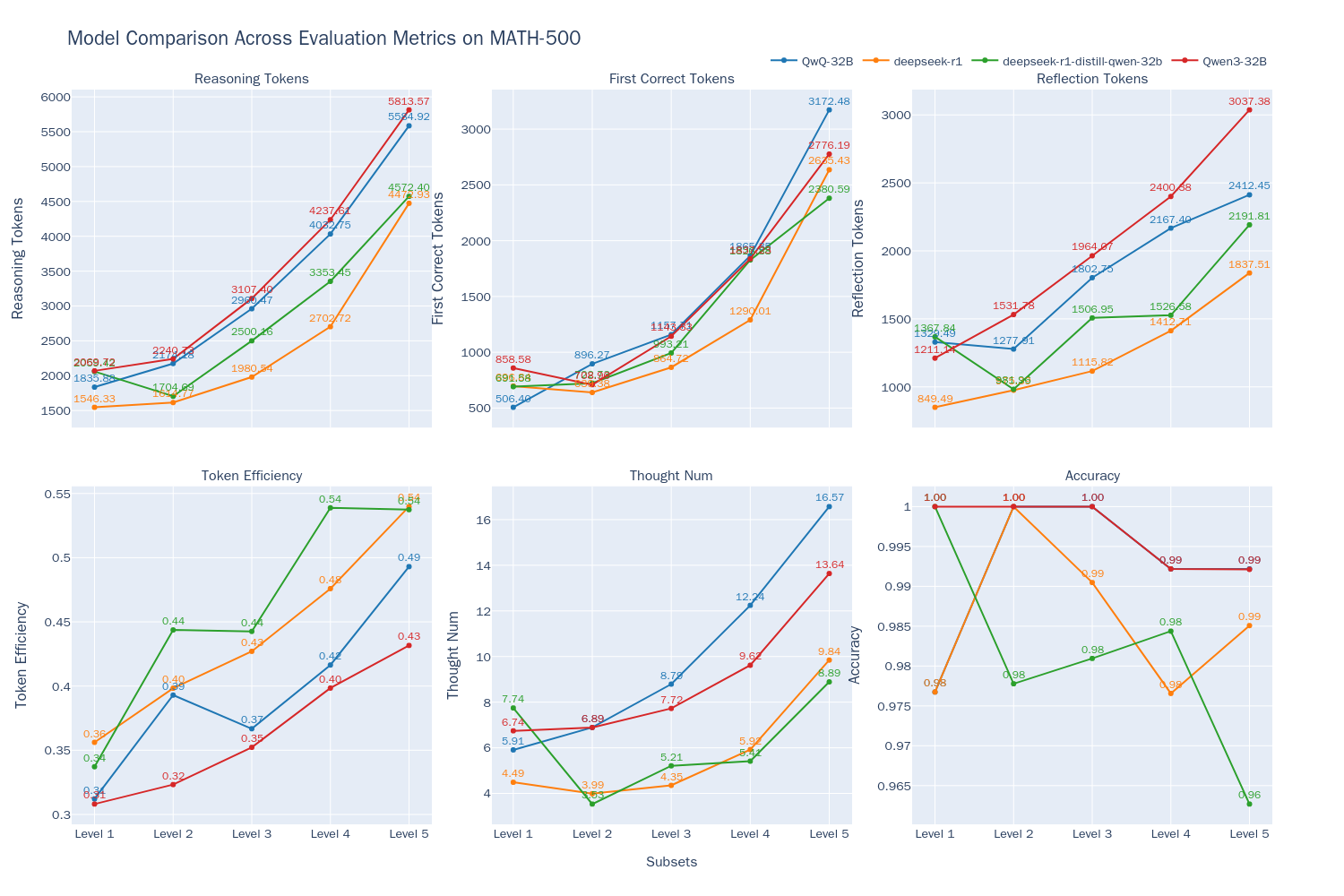
看两个独立测评
evalscope 做了测试,结果 - Qwen3-32B 模型在思考模式下,其准确率与 QwQ-32B 相当(在 Accuracy 折线上两者重合),都达到了最好的水平。随着问题难度的增加,模型的输出长度都随问题难度增加而增加,这表明模型在解答更复杂问题时需要更长的"思考时间",与 Inference-Time Scaling 现象相符。
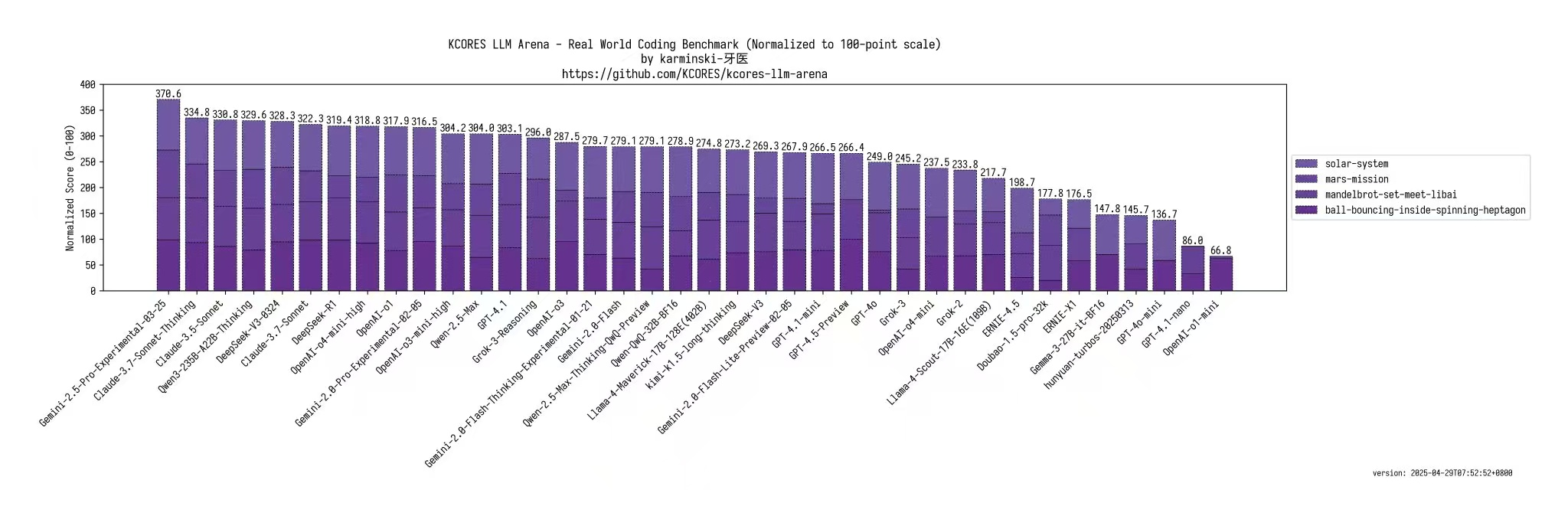
推上 karminski3 测试了其写代码能力
极简结论:Qwen3 是可以本地部署的最强开源写代码大模型

制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)图解机器学习 - 中文版(72 张 PNG)ChatGPT、大模型系列研究报告(50 个 PDF)108 页 PDF 小册子:搭建机器学习开发环境及 Python 基础 116 页 PDF 小册子:机器学习中的概率论、统计学、线性代数 史上最全!371 张速查表,涵盖 AI、ChatGPT、Python、R、深度学习、机器学习等